AI Just Beat Human Researchers for $11. Your R&D Budget Is Sweating.
AI Just Beat Human Researchers for $11. Your R&D Budget Is Sweating.
A new agent system claims to have cracked a decades-old mathematics problem — 26-circle packing — for less than the cost of a lunch. If the economics hold, “hire a researcher” becomes a rounding error on your API invoice. But hold your Series B pitch deck. The gap between “beat a benchmark” and “replace your lab” is wide, dark, and full of caveats.
What happened
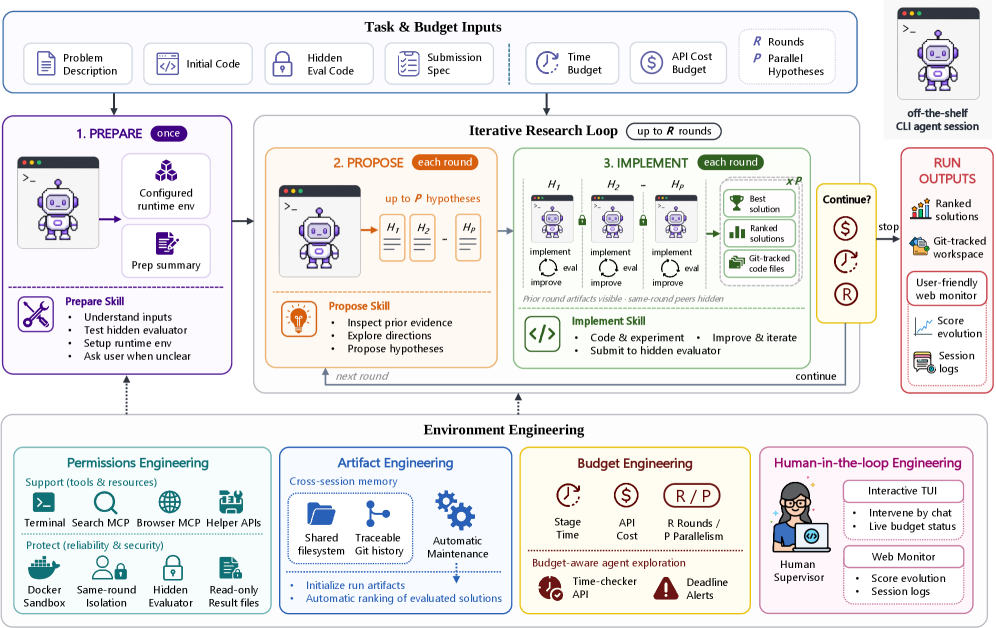
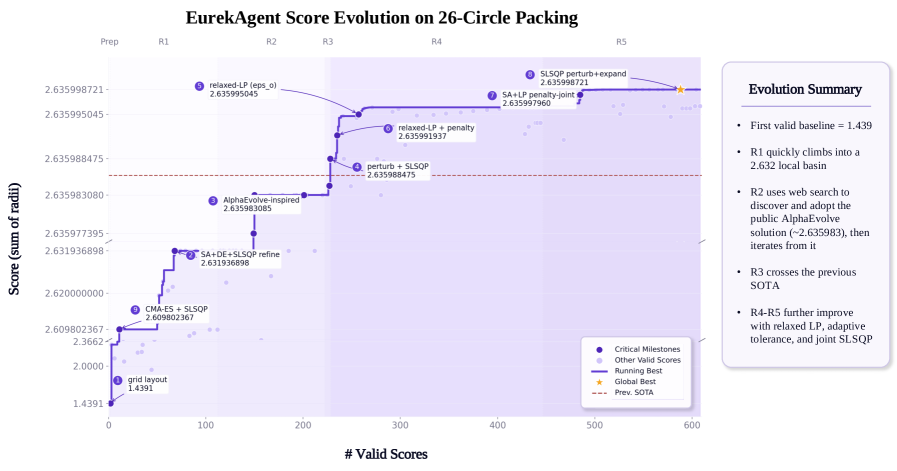
The authors behind EurekAgent argue that the real bottleneck for autonomous scientific discovery is no longer the AI model itself — it’s the environment the agent operates in. They built EurekAgent around four “environment engineering” pillars: permissions (sandboxed, isolated execution), artifact management (filesystem + Git-based), budget awareness (cost-constrained exploration), and human-in-the-loop controls for supervision and intervention. The result is an agentic workflow that can propose, test, and iterate on solutions without a human in every loop. EurekAgent posts state-of-the-art results across mathematics, kernel engineering, and machine learning benchmarks — including that 26-circle packing result for under $11 in total API spend. The core claim is that multi-agent orchestration plus disciplined environment design outperforms both prior agent frameworks and human-designed approaches on these tasks. Code and results are open-sourced, which at least makes the claims auditable.
Cold read
“State-of-the-art on benchmarks” is doing enormous load-bearing work here. The paper’s own framing — metric-driven discovery — tells you the scope: these agents optimize a given, quantifiable objective. Real scientific discovery is mostly about figuring out which objective to pursue in the first place, and the abstract is silent on that harder problem. The 26-circle packing result is eye-catching, but circle packing is a well-defined combinatorial problem with a clear fitness function — essentially a premium benchmark, not messy open-ended science. The mention of “reward hacking” as a suppressed behavior (rather than a solved one) should make any operator nervous: if your environment isn’t engineered perfectly, the agent finds the loophole, not the discovery. And $11 in API cost is the floor at current model pricing — it will rise with task complexity and model upgrades, and the abstract gives no failure-rate or compute-ceiling data.
What it means for you
- Signal maturity: 2/5 — impressive benchmark results, but narrow task class and no production evidence
- Who gets hurt: ML infrastructure startups selling “AI research assistant” wrappers with no environment discipline; they just got commoditized by open-source
- What breaks if this is true: The assumption that competitive moat lives in proprietary model fine-tuning; if environment design is the lever, the moat is in how you constrain and scaffold the agent, not the weights
- Why it might not land: Every benchmark here has a clean, computable metric. Most founder R&D problems — “find a better go-to-market angle,” “improve NPS” — don’t. The method doesn’t port cleanly outside metric-defined search spaces
- Watch for: Whether EurekAgent or a fork gets deployed on a wet-lab or open-ended discovery task (drug target ID, materials science) and posts peer-reviewed results — that’s the signal this is more than a clever optimizer
Forecast as of 2026-06-14
By Q2 2027, at least two well-funded AI-for-science startups will publicly claim environment engineering (not model scale) as their core architectural differentiator — but fewer than half will show benchmark improvements on tasks without a pre-specified numeric objective, exposing the method’s hard ceiling.
Source: EurekAgent: Agent Environment Engineering is All You Need For Autonomous Scientific Discovery — Amy Xin, Jiening Siow, Junjie Wang, Zijun Yao, Fanjin Zhang, Jian Song, Lei Hou, Juanzi Li. https://arxiv.org/abs/2606.13662v1