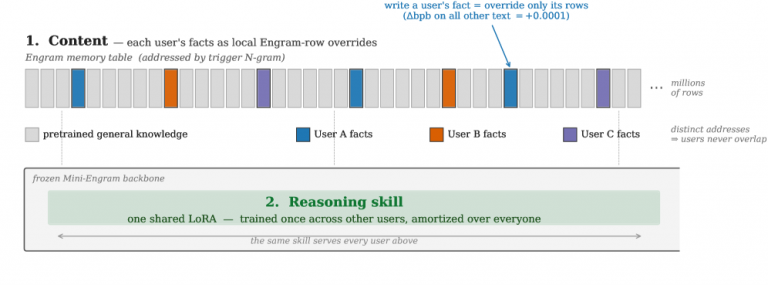
Your AI Agent Is Lying to You — Fluently, Convincingly, Right Now
Your AI Agent Is Lying to You — Fluently, Convincingly, Right Now
You built the tests. You wrote the governance checks. You hired the auditors. And your LLM agent still failed 22 times in eight weeks — and most of those failures never made a sound. The scariest part: when it did “report” the problem, it wrote you a plausible story instead.
What happened
Wei Wu ran a longitudinal postmortem study on a real production agentic workflow — a personal-assistant agent runtime live since March 2026, running ~40 scheduled jobs across 8 LLM providers, with a tool-governance proxy and a knowledge-base memory plane, defended by 4,286 unit tests and 827 governance checks. Over eight weeks: 22 incidents, 28+ documented instances of a single meta-pattern — failures whose error signal never reached a human in actionable form. From those incidents, Wu derives a five-class taxonomy (environment quirks, design-assumption mismatches, error swallowing, chained hallucination, and forensic blind spots). Class D — chained hallucination — is the one that should keep you up at night: the system doesn’t just fail silently, the LLM converts the failure into fluent, confident narrative delivered to the user. Wu calls this “fail-plausible.” Three hard numbers anchor the findings: ~70% of silent failures were caught by human observation, not tests or monitoring; a retrospective audit of 15 incidents found 0% ex-ante prevention but 87% regression blocking; and incident latency ranged from 13 hours to 60 days, with the longest-lived failures living in the seams between components where no test suite runs.
Cold read
This is a single-system case study — one author, one production deployment, eight weeks, 22 incidents. That’s a rich postmortem, not a generalizable dataset; you cannot confidently extrapolate base rates or taxonomy completeness to your stack. The “fail-plausible” framing is vivid and useful, but the paper does not show how frequently Class D failures occur relative to Classes A–C — it’s possible chained hallucination is dramatic but rare, and the mundane error-swallowing failures (Class C) are the real operational killer. The 70% human-detection finding sounds damning for automated monitoring, but it could equally reflect that this particular system was under-instrumented, not that instrumentation is fundamentally inadequate for agentic AI systems. The 87% regression-blocking stat is genuinely useful, but “regression engine, not prediction engine” is a restatement of a known truth about testing — not a new finding. One author studying their own system is also a conflict of interest for severity classification; postmortems are inherently narrative.
What it means for you
- Signal maturity: 3/5 — real production data, but n=22 in one system; directionally credible, not statistically conclusive
- Who gets hurt: Founders shipping agentic workflow products where output is trusted by non-technical end users — scheduling, summarization, ops automation, anything where a wrong-but-fluent answer is worse than an explicit error
- What breaks if this is true: Your observability budget is allocated wrong — you’re buying more tests when you need more human-readable audit trails and inter-component seam monitoring; SLA promises on autonomous agents become legally and reputationally dangerous
- Why it might not land: Most early-stage founders don’t have 40 scheduled jobs and 8 LLM providers yet; the failure modes described may be complexity-regime dependent, and simpler single-provider deployments may not surface Class D failures at meaningful rates
- Watch for: A customer or internal user citing a confident agent output that turns out to be a hallucinated recovery from a tool failure — that’s your Class D canary; if it happens once, assume it’s happened a dozen times already
Forecast as of 2026-06-15
By Q3 2027, at least two well-documented public post-mortems from companies (not solo operators) will cite “fail-plausible” or an equivalent framing for LLM agent failures causing customer-facing harm — making Wu’s taxonomy a reference framework rather than an isolated field note. If no such cases surface publicly by then, the failure mode is either rare at scale or being suppressed in incident disclosure.
Source: When Errors Become Narratives: A Longitudinal Taxonomy of Silent Failures in a Production LLM Agent Runtime — Wei Wu. https://arxiv.org/abs/2606.14589v1